
Code
library(rpart)
library(rpart.plot)
cars_fit <- rpart(Price ~ ., data = cu.summary, minbucket = 1, cp = 0)
rpart.plot(cars_fit, tweak = 2)
From a course by Anne Ruiz-Gazen
Predict the land use of a given area (agriculture, forest, etc.) given satellite information, meteorological data, socio-economic information, prices information, etc.
Predict high risk for heart attack:
Determine how computer performance is related to a number of variables which describe the features of a PC (the size of the cache, the cycle time of the computer, the memory size and the number of channels. Both the last two were not measured but minimum and maximum values obtained).

Decision trees are well designed for
but they face several difficulties:
The algorithm is based on two steps:
library(rpart)
library(rpart.plot)
cars_fit <- rpart(Price ~ ., data = cu.summary, minbucket = 1, cp = 0)
rpart.plot(cars_fit, tweak = 2)The subgroups of data created by the partitioning are called nodes.
The subgroups of data created by the partitioning are called nodes.
The data is built from a pair of random variables, \((X,Y)\), where \(X\) is made of \(p\) qualitative or quantitative predictors, \(X^1, \dots, X^p\), and \(Y\) is a qualitative (classification) or quantitative (regression) variable to predict from \(X\).
The data consists in \(n\) i.i.d. observations \((x_1,y_1), \dots, (x_n,y_n)\) of \((X,Y)\).
As explained previously, building a decision tree aims at finding a series of:
In the following, we will note the nodes with the following convention:
When splitting \((y_i)_i\) into two groups, we aim at having two non empty groups with \(Y\) values as homogeneous as possible.
Then, we have to define an homogeneity criterion for each node, i.e. a function \[H:\mathcal{N} \rightarrow \mathbb{R}_+\] that is
The split of a node \(\mathcal{N}^m_k\) is chosen, among all possible splits, by minimizing the sum of the homogeneity of the corresponding child nodes: \[\arg\max_{\textrm{splits of }\mathcal{N}^m_k} H(\mathcal{N}^m_k) - \left(n_1 H(\mathcal{N}^{m+1}_{2k-1}) + n_2 H(\mathcal{N}^{m+1}_{2k}\right)/(n_1+n_2).\]
Consider a given node \(\mathcal{N}^m_k\) that has to be split into two classes (two new child nodes) and denote by
library(ggplot2)
set.seed(0)
a <- data.frame(X_1 = rnorm(800), X_2 = rnorm(800), Y = as.factor("A"))
b <- data.frame(X_1 = rnorm(200, 2), X_2 = rnorm(200, 2), Y = as.factor("B"))
ab <- rbind(a, b)
ggplot(ab, aes(X_1, X_2, color = Y, label = Y)) +
geom_point()
library(parttree)
ab_fit <- rpart(Y ~ ., data = ab, minbucket = nrow(ab), cp = 0)
rpart.plot(ab_fit, box.palette = "RdBu")
ggplot(ab, aes(X_1, X_2, color = Y, label = Y)) +
geom_point()
for (i in 1:3) {
ab_fit <- rpart(Y ~ ., data = ab, maxdepth = i, cp = -Inf)
rpart.plot(ab_fit, box.palette = "RdBu")
p <- ggplot(ab, aes(X_1, X_2, color = Y, fill = Y)) +
geom_parttree(data = ab_fit, alpha = 0.1, flip = i == 1) +
geom_point()
print(p)
}







We consider the split: \(X_1 <\) 1.64.
ab$split <- ifelse(ab$X_1 < ab_fit$splits[1, 4], "Left", "Right")
dplyr::sample_n(ab, 10)| X_1 | X_2 | Y | split |
|---|---|---|---|
| -1.5017872 | 1.6803619 | A | Left |
| -0.9233743 | -0.8534551 | A | Left |
| 1.5462761 | 3.3774228 | B | Left |
| -0.8320433 | 1.1174336 | A | Left |
| -1.0854224 | 2.2061932 | A | Left |
| 0.9922884 | 0.0171323 | A | Left |
| 2.6586580 | 0.3255937 | A | Right |
| -0.1726686 | -0.2422814 | A | Left |
| -0.8874201 | -0.9109120 | A | Left |
| -1.1729836 | -1.6521118 | A | Left |
ab_ct <- table(ab$split, ab$Y) |>
addmargins() |>
as.data.frame.matrix()
ab_ct| A | B | Sum | |
|---|---|---|---|
| Left | 766 | 63 | 829 |
| Right | 34 | 137 | 171 |
| Sum | 800 | 200 | 1000 |
ab_freqs <- ab_ct$Sum / ab_ct$Sum[3]
(ab_probs <- ab_ct / ab_ct$Sum)| A | B | Sum | |
|---|---|---|---|
| Left | 0.9240048 | 0.0759952 | 1 |
| Right | 0.1988304 | 0.8011696 | 1 |
| Sum | 0.8000000 | 0.2000000 | 1 |
ab_probs$Freq <- ab_freqs
ab_probs$Gini <- 1 - ab_probs$A^2 - ab_probs$B^2
ab_probs| A | B | Sum | Freq | Gini | |
|---|---|---|---|---|---|
| Left | 0.9240048 | 0.0759952 | 1 | 0.829 | 0.1404398 |
| Right | 0.1988304 | 0.8011696 | 1 | 0.171 | 0.3185938 |
| Sum | 0.8000000 | 0.2000000 | 1 | 1.000 | 0.3200000 |
The total difference in Gini index of this split is:
with(ab_probs, Freq[3] * Gini[3] - Freq[2] * Gini[2] - Freq[1] * Gini[1])[1] 0.1490959The growing of the tree is stopped if the obtained node is homogeneous or if the number of observations in the nodes is smaller than a fixed number (generally chosen between 1 and 5).
As said earlier it has been found that the best method of arriving at a suitable size for the tree is to grow an overly complex one then to prune it back. The pruning is based on the misclassification rate (number of observations misclassified divided by the total number of observations, see also confusion table). However the error rate will always drop (or at least not increase) with every split. This does not mean however that the error rate on the test data will improve.
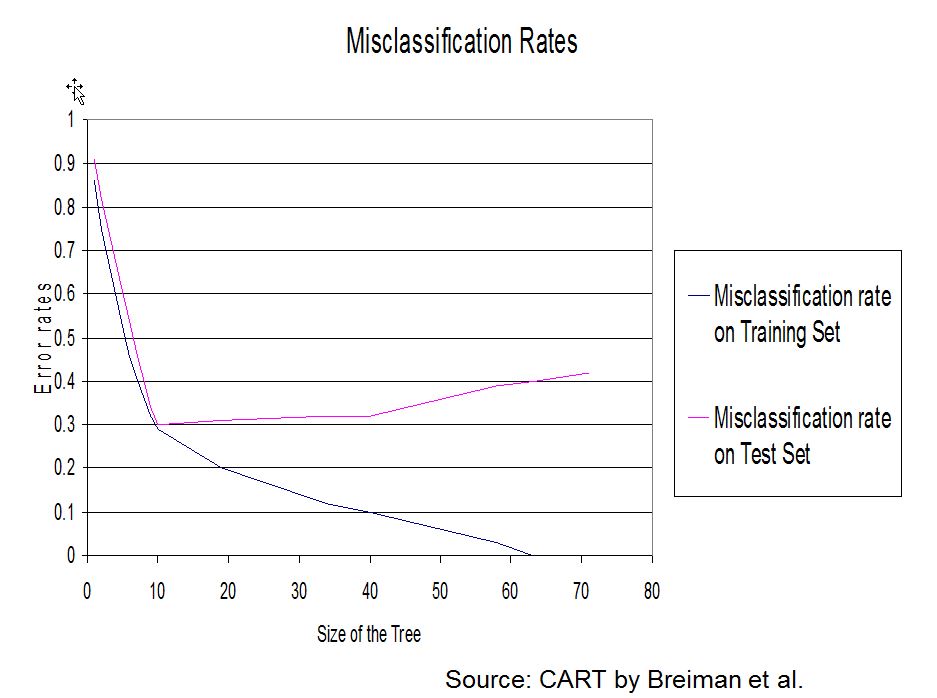
To overcome the overfitting problem (good results on the training set but bad results on the test set).
A solution is to choose one of the subtree of the maximal tree obtained by iterative pruning and to choose the optimal subtree for a given quality criterion. This step-by-step methodology do not necessarily lead to a global optimal subtree but it is a computationally plausible solution.
The idea of pruning is to estimate an error criterion penalized by the complexity of the model.
More precisely, suppose that we have obtained the tree \(\mathcal{T}\) with leafs \(\mathcal{F}_1\), …, \(\mathcal{F}_K\) (so \(K\) is the number of leafs) having predicting values \(\mathcal{Y}_1\), …, \(\mathcal{Y}_K\). Then, the error of \(\mathcal{T}\) is \[\textcolor{blue}{L\mathcal{T}}=\sum_{k=1}^K L\mathcal{F}_k\qquad \mbox{ where }\textcolor{blue}{L\mathcal{F}_k} = \sum_{i:\ x_i\in\mathcal{F}_k} (y_i-\mathcal{Y}_k)^2\] for the regression case and the misclassification rate for the classification case.
Hence, a penalized version of the error that takes into account the complexity of the tree can be defined through: \[\textcolor{blue}{L_\gamma\mathcal{T}} = L\mathcal{T} + \gamma K.\] where \(K\) is the size of the tree (number of terminal nodes).
When \(\gamma=0\), \(L_\gamma\mathcal{T}=L\mathcal{T}\) and hence the tree optimizing this criterion is \(\mathcal{T}\) (which has been designed for).
When \(\gamma\) is increasing, one of the nodes’ split, \(\mathcal{S}_{j}\) appears such that: \[L_\gamma \mathcal{T} > L_\gamma \mathcal{T}^{-\mathcal{S}_{j}}\] where \(\mathcal{T}^{-\mathcal{S}_{j}}\) is the tree where the split \(\mathcal{S}_{j}\) has been removed. Let us call \(\mathcal{T}_{K-1}\) this new tree.
This process is iterated to obtain a sequence of trees \[\mathcal{T} \supset \mathcal{T}_{K-1} \supset \ldots \mathcal{T}_{1}\] where \(\mathcal{T}_{1}\) is the tree restricted to its root.
The optimal subtree is chosen by validation or cross-validation by the following algorithm: Algorithm for cross validation choice
rpart R functionrpart in R and the results are accessible using printcp and plotcp where cp denotes the complexity parameter (\(\gamma\) for printcp but geometric mean of the interval bounds for plotcp).rpart.plot(cars_fit)Warning: labs do not fit even at cex 0.15, there may be some overplotting
printcp(cars_fit)
Regression tree:
rpart(formula = Price ~ ., data = cu.summary, minbucket = 1,
cp = 0)
Variables actually used in tree construction:
[1] Country Mileage Reliability Type
Root node error: 7407472615/117 = 63311732
n= 117
CP nsplit rel error xerror xstd
1 2.5052e-01 0 1.00000 1.01505 0.16021
2 1.4836e-01 1 0.74948 0.89086 0.16280
3 8.7654e-02 2 0.60112 0.75521 0.15281
4 6.2818e-02 3 0.51347 0.60889 0.10346
5 3.4875e-02 4 0.45065 0.56748 0.10129
6 2.4396e-02 5 0.41577 0.64242 0.12571
7 1.1966e-02 8 0.34259 0.66476 0.12901
8 1.0640e-02 14 0.27079 0.70868 0.14930
9 9.9092e-03 15 0.26015 0.71633 0.15026
10 8.8587e-03 16 0.25024 0.71970 0.15017
11 7.3572e-03 20 0.21480 0.72697 0.15024
12 7.2574e-03 22 0.20009 0.73679 0.15046
13 3.8972e-03 28 0.15655 0.74722 0.15038
14 1.9968e-03 31 0.14334 0.76297 0.15290
15 1.9131e-03 33 0.13935 0.77438 0.15355
16 1.6070e-03 34 0.13744 0.77296 0.15354
17 1.1151e-03 35 0.13583 0.77317 0.15337
18 9.0617e-04 36 0.13471 0.77938 0.15474
19 4.7736e-04 42 0.12928 0.77484 0.15418
20 1.4084e-04 43 0.12880 0.77687 0.15415
21 1.0325e-04 45 0.12852 0.77767 0.15415
22 1.0187e-04 46 0.12841 0.77751 0.15415
23 8.0922e-05 47 0.12831 0.77749 0.15415
24 6.9751e-05 48 0.12823 0.77810 0.15413
25 6.0368e-05 49 0.12816 0.77810 0.15413
26 5.2584e-05 50 0.12810 0.77797 0.15413
27 5.1761e-05 52 0.12800 0.77797 0.15413
28 2.5252e-05 53 0.12794 0.77721 0.15414
29 1.2155e-05 54 0.12792 0.77792 0.15414
30 7.9655e-06 55 0.12791 0.77791 0.15414
31 1.5920e-06 56 0.12790 0.77791 0.15414
32 4.1013e-07 57 0.12790 0.77789 0.15414
33 0.0000e+00 58 0.12790 0.77792 0.15414plotcp(cars_fit)
cars_fit <- prune(cars_fit, cp = 0.074)
rpart.plot(cars_fit)
# Data
candidates <- read.table("data_dt.txt", header = TRUE)
# Transformation of the variable to predict into a factor
candidates$Res <- as.factor(candidates$Res)
candidates| Obs | Id | Dip | Test | Exp | Res |
|---|---|---|---|---|---|
| 1 | A | 1 | 5 | 4 | 0 |
| 2 | B | 2 | 3 | 3 | 0 |
| 3 | C | 1 | 4 | 5 | 1 |
| 4 | D | 2 | 3 | 4 | 0 |
| 5 | E | 1 | 4 | 4 | 0 |
| 6 | F | 4 | 3 | 4 | 1 |
| 7 | G | 3 | 4 | 4 | 1 |
| 8 | H | 1 | 1 | 5 | 0 |
| 9 | I | 3 | 2 | 5 | 1 |
| 10 | J | 5 | 4 | 4 | 1 |
# Classification tree
library(rpart)
library(rpart.plot)
# Building the tree (prune is not useful here)
candidates_fit <- rpart(Res ~ Dip + Test + Exp,
data = candidates, method = "class",
parms = list(split = "gini"), control = rpart.control(minsplit = 2)
)# Plot
rpart.plot(candidates_fit)
summary(candidates_fit)Call:
rpart(formula = Res ~ Dip + Test + Exp, data = candidates, method = "class",
parms = list(split = "gini"), control = rpart.control(minsplit = 2))
n= 10
CP nsplit rel error xerror xstd
1 0.80 0 1.0 2.0 0.0000000
2 0.10 1 0.2 0.2 0.1897367
3 0.01 3 0.0 0.6 0.2898275
Variable importance
Dip Test Exp
67 20 13
Node number 1: 10 observations, complexity param=0.8
predicted class=0 expected loss=0.5 P(node) =1
class counts: 5 5
probabilities: 0.500 0.500
left son=2 (6 obs) right son=3 (4 obs)
Primary splits:
Dip < 2.5 to the left, improve=3.3333330, (0 missing)
Test < 1.5 to the left, improve=0.5555556, (0 missing)
Exp < 3.5 to the left, improve=0.5555556, (0 missing)
Node number 2: 6 observations, complexity param=0.1
predicted class=0 expected loss=0.1666667 P(node) =0.6
class counts: 5 1
probabilities: 0.833 0.167
left son=4 (4 obs) right son=5 (2 obs)
Primary splits:
Exp < 4.5 to the left, improve=0.6666667, (0 missing)
Test < 3.5 to the left, improve=0.3333333, (0 missing)
Dip < 1.5 to the right, improve=0.1666667, (0 missing)
Node number 3: 4 observations
predicted class=1 expected loss=0 P(node) =0.4
class counts: 0 4
probabilities: 0.000 1.000
Node number 4: 4 observations
predicted class=0 expected loss=0 P(node) =0.4
class counts: 4 0
probabilities: 1.000 0.000
Node number 5: 2 observations, complexity param=0.1
predicted class=0 expected loss=0.5 P(node) =0.2
class counts: 1 1
probabilities: 0.500 0.500
left son=10 (1 obs) right son=11 (1 obs)
Primary splits:
Test < 2.5 to the left, improve=1, (0 missing)
Node number 10: 1 observations
predicted class=0 expected loss=0 P(node) =0.1
class counts: 1 0
probabilities: 1.000 0.000
Node number 11: 1 observations
predicted class=1 expected loss=0 P(node) =0.1
class counts: 0 1
probabilities: 0.000 1.000 rpart.plot(candidates_fit, extra = 101)
rpart.plot(candidates_fit, extra = 103)
# Rules
rpart.rules(candidates_fit)| Res | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 0.00 | when | Dip | < | 3 | & | Exp | < | 5 | ||||
| 10 | 0.00 | when | Dip | < | 3 | & | Exp | >= | 5 | & | Test | < | 3 |
| 11 | 1.00 | when | Dip | < | 3 | & | Exp | >= | 5 | & | Test | >= | 3 |
| 3 | 1.00 | when | Dip | >= | 3 |
# Prediction
predict(candidates_fit, candidates, type = "class") 1 2 3 4 5 6 7 8 9 10
0 0 1 0 0 1 1 0 1 1
Levels: 0 1predict(candidates_fit, candidates, type = "prob") 0 1
1 1 0
2 1 0
3 0 1
4 1 0
5 1 0
6 0 1
7 0 1
8 1 0
9 0 1
10 0 1predict(candidates_fit, candidates, type = "matrix") [,1] [,2] [,3] [,4] [,5] [,6]
1 1 4 0 1 0 0.4
2 1 4 0 1 0 0.4
3 2 0 1 0 1 0.1
4 1 4 0 1 0 0.4
5 1 4 0 1 0 0.4
6 2 0 4 0 1 0.4
7 2 0 4 0 1 0.4
8 1 1 0 1 0 0.1
9 2 0 4 0 1 0.4
10 2 0 4 0 1 0.4# confusion table
candidates_predict <- predict(candidates_fit, candidates, type = "vector")
table(candidates_predict, candidates$Res)
candidates_predict 0 1
1 5 0
2 0 5# prediction of a new observations
predict(candidates_fit, newdata = data.frame(Dip = c(1, 2, 2), Exp = c(5, 5, 3), Test = c(3, 1, 5)), type = "vector")1 2 3
2 1 1 # Pruning
# print and plot the complexity parameter (cp)
printcp(candidates_fit)
Classification tree:
rpart(formula = Res ~ Dip + Test + Exp, data = candidates, method = "class",
parms = list(split = "gini"), control = rpart.control(minsplit = 2))
Variables actually used in tree construction:
[1] Dip Exp Test
Root node error: 5/10 = 0.5
n= 10
CP nsplit rel error xerror xstd
1 0.80 0 1.0 2.0 0.00000
2 0.10 1 0.2 0.2 0.18974
3 0.01 3 0.0 0.6 0.28983plotcp(candidates_fit)
candidates_fit_prune <- prune(candidates_fit, cp = 0.2)
rpart.plot(candidates_fit_prune)
# Prediction on the pruned data set
predict(candidates_fit_prune, candidates, type = "matrix") [,1] [,2] [,3] [,4] [,5] [,6]
1 1 5 1 0.8333333 0.1666667 0.6
2 1 5 1 0.8333333 0.1666667 0.6
3 1 5 1 0.8333333 0.1666667 0.6
4 1 5 1 0.8333333 0.1666667 0.6
5 1 5 1 0.8333333 0.1666667 0.6
6 2 0 4 0.0000000 1.0000000 0.4
7 2 0 4 0.0000000 1.0000000 0.4
8 1 5 1 0.8333333 0.1666667 0.6
9 2 0 4 0.0000000 1.0000000 0.4
10 2 0 4 0.0000000 1.0000000 0.4