
[1] -0.08058779 0.28044078 1.19011050 -1.25212790High-Dimensional Data Analysis and Machine Learning
From a course by Davy Paindaveine and Nathalie Vialaneix
Last updated on October 1, 2024
How to estimate the accuracy of \(\hat{\lambda}_\text{opt}\)?
- \(\dots\) i.e., its standard deviation \(\text{Std}[\hat{\lambda}_\text{opt}]\)?
- Using the available sample, we observe \(\hat{\lambda}_\text{opt}\) only once.
- We need further samples leading to further observations of \(\hat{\lambda}_\text{opt}\).

Sampling from the population: infeasible
We generated 1000 samples from the population. The first three are

- This allows us to compute: \(\bar{\lambda}_\text{opt} = \frac{1}{1000} \sum_{i=1}^{1000} \hat{\lambda}^{(i)}_\text{opt}\)
- Then: \(\widehat{\text{Std}[\hat{\lambda}_\text{opt}]} = \sqrt{\frac{1}{999} \sum_{i=1}^{1000} (\hat{\lambda}^{(i)}_\text{opt} - \bar{\lambda}_\text{opt})^2}\).
Here: \[ \widehat{\text{Std}[\hat{\lambda}_\text{opt}]} \approx 0.077, \qquad \bar{\lambda}_\text{opt} \approx 0.331 \ \ (\approx \lambda_\text{opt} = \frac13 = 0.333) \]

Figure 3: Histogram and boxplot of the empirical distribution of the \(\hat{\lambda}^{(i)}_\text{opt}\) (James et al. 2021).
(This could also be used to estimate quantiles of \(\hat{\lambda}_\text{opt}\).)
This provides \[ \widehat{\text{Std}[\hat{\lambda}_\text{opt}]}^* \approx 0.079 \]

Figure 4: Histogram and boxplot of the bootstrap distribution of \(\hat\lambda_\text{opt}\) (James et al. 2021).
(This could again be used to estimate quantiles of \(\hat{\lambda}_\text{opt}\).)
A comparison between both samplings
Results are close: \(\widehat{\text{Std}[\hat{\lambda}_\text{opt}]}\approx 0.077\) and \(\widehat{\text{Std}[\hat{\lambda}_\text{opt}]}^*\approx 0.079\).


Classification trees
In Part 1 of this course, we learned about a special type of classifiers \(\phi_{\mathcal{S}}\), namely classification trees.

(+) Interpretability
(+) Flexibility
(–) Stability
(–) Performance
Toy illustration: bagging with \(B=3\) trees

entry=782
time=127
cens=1
\(\quad \Downarrow\)
Female

entry=782
time=127
cens=1
\(\quad \Downarrow\)
Male

entry=782
time=127
cens=1
\(\quad \Downarrow\)
Male

Figure 6: Results of the simulation (Q-Q plot and boxplot).
(2) Compute an \(L\)-fold cross-validation error:
Partition the data set \(\mathcal{S}\) into \(L\) folds \(\mathcal{S}_{\ell}\), \(\ell=1,\ldots,L\). For each \(\ell\), evaluate the test error \(e_{\text{test},\ell}\) associated with training set \(\mathcal{S}\setminus\mathcal{S}_{\ell}\) and test set \(\mathcal{S}_{\ell}\).
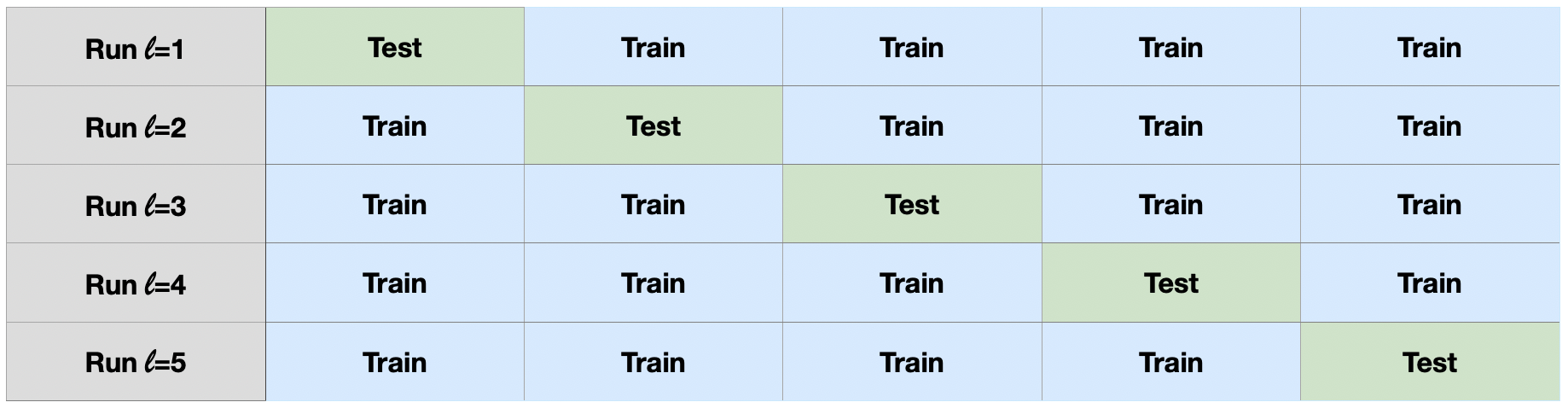
The quantity \[ e_\text{CV}=\frac{1}{L}\sum_{\ell=1}^L e_{\text{test},\ell} \] is then the (\(L\)-fold) ‘cross-validation error’.
The results

Figure 8: Comparison of single tree, bagging and random forest errors
Measuring importance of each predictor

Figure 9: Importance of each predictor (decreasing order)
References

Breiman, Leo. 1996. “Bagging Predictors.” Machine Learning 24 (2): 123–40. https://doi.org/10.1007/BF00058655.
Breiman, Leo, Jerome H. Friedman, Richard A. Olshen, and Charles J. Stone. 1984. Classification and Regression Trees. 1st ed. Routledge. https://doi.org/10.1201/9781315139470.
Efron, B. 1979. “Bootstrap Methods: Another Look at the Jackknife.” The Annals of Statistics 7 (1). https://doi.org/10.1214/aos/1176344552.
Ho, Tin Kam. 1995. “Random Decision Forests.” In Proceedings of 3rd International Conference on Document Analysis and Recognition, 1:278–282 vol.1. https://doi.org/10.1109/ICDAR.1995.598994.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2021. An Introduction to Statistical Learning: With Applications in r. Springer Texts in Statistics. New York, NY: Springer US. https://doi.org/10.1007/978-1-0716-1418-1.