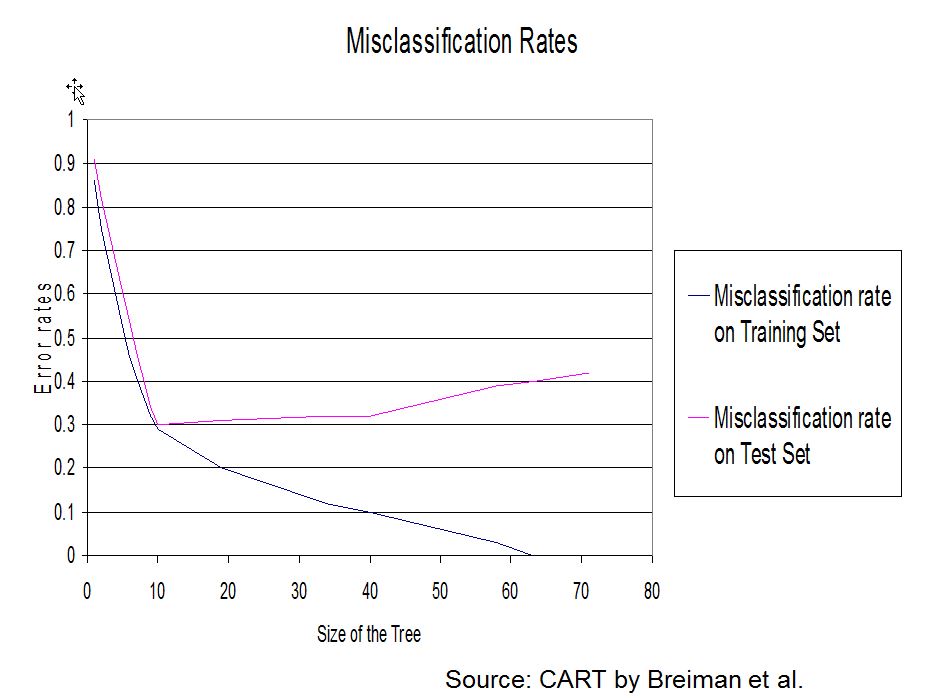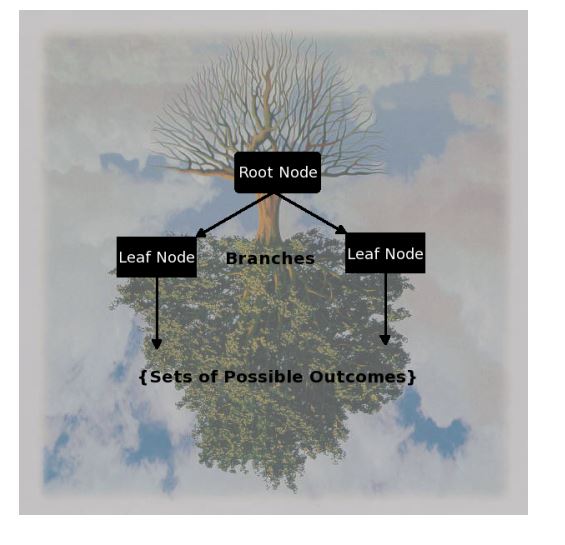
Code
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import dtreeviz as dt
candidates = pd.read_csv("data/recruitment.csv")
candidates
features = ["Exp", "Dip", "Test"]
output = "Res"
clf = DecisionTreeClassifier().fit(candidates[features], candidates[output])
export_graphviz(
clf,
"images/recruitment_tree.dot",
feature_names=features,
class_names=["Rejected", "Accepted"],
filled=True,
)
clf_viz = dt.model(
clf,
candidates[features],
candidates[output],
feature_names=features,
target_name=output,
class_names=["Rejected", "Accepted"],
)
clf_viz.view()